Fork&Join框架介绍
一、概述
Fork/Join 是 JDK 1.7 加入的新的线程池实现,它体现的是一种分治思想,适用于能够进行任务拆分的CPU密集型运算。
- 所谓的任务拆分,是将一个大任务拆分为算法上相同的小任务,直至不能拆分可以直接求解。跟递归相关的一些计算,如归并排序、斐波那契数列、都可以用分治思想进行求解。
- Fork/Join 在分治的基础上加入了多线程,可以把每个任务的分解和合并交给不同的线程来完成,进一步提升了运算效率。
- Fork/Join 默认会创建与CPU核心数大小相同的线程池。
二、Fork/Join框架介绍
Fork/Join框架主要包含三个模块:
- 线程池:
ForkJoinPool - 任务对象:
ForkJoinTask(包括RecursiveTask、RecursiveAction和CountedCompleter) - 执行Fork/Join任务的线程:
ForkJoinWorkerThread
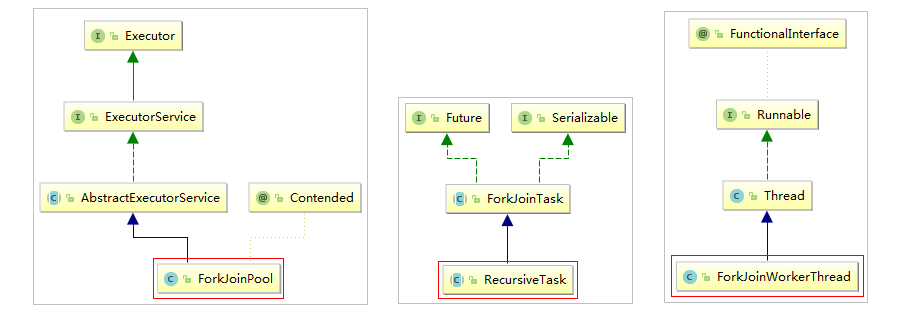
三者的关系
ForkJoinPool可以通过池中的ForkJoinWorkerThread来处理ForkJoinTask任务。
ForkJoinPool 只接收 ForkJoinTask 任务(在实际使用中,也可以接收 Runnable/Callable 任务,但在真正运行时,也会把这些任务封装成 ForkJoinTask 类型的任务),RecursiveTask 是 ForkJoinTask 的子类,是一个可以递归执行的 ForkJoinTask,RecursiveAction 是一个无返回值的 RecursiveTask,CountedCompleter 在任务完成执行后会触发执行一个自定义的钩子函数。
在实际运用中,我们一般都会继承 RecursiveTask 、RecursiveAction 或 CountedCompleter 来实现我们的业务需求,而不会直接继承 ForkJoinTask 类。
三、Fork/Join框架核心思想
3.1 分治思想(Divide-and-Conquer)
分治算法(Divide-and-Conquer)把任务递归的拆分为各个子任务,这样可以更好的利用系统资源,尽可能的使用所有可用的计算能力来提升应用性能。
首先看一下 Fork/Join 框架的任务运行机制如下图所示:
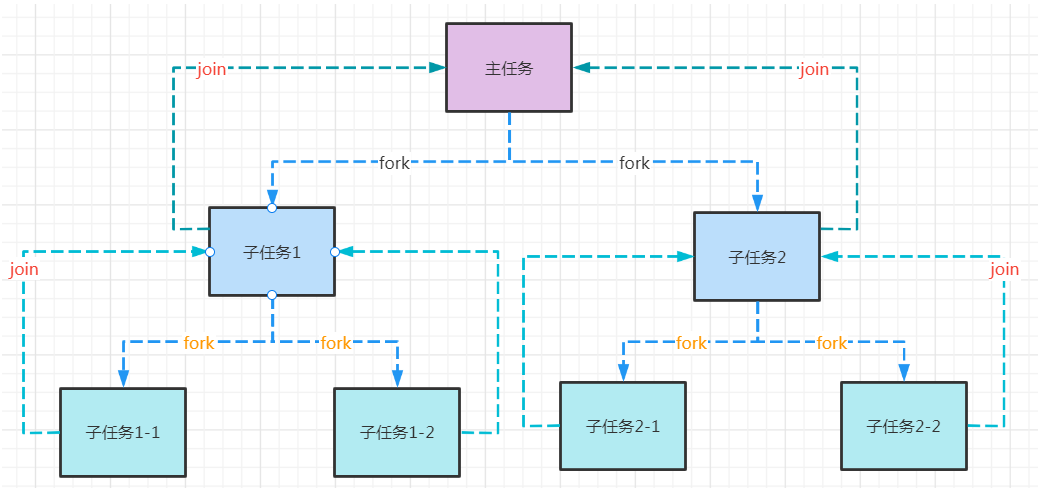
- **fork()**:开启一个新线程(或是重用线程池内的空闲线程),将任务交给该线程处理。
- **join()**:等待该任务的处理线程处理完毕,获得返回值。
当然并不会每个 fork 都会创建新线程, 也不是每个 join 都会造成线程被阻塞, 而是采取work-stealing 原理。
3.2 work-stealing(工作窃取)算法
线程池内的所有工作线程都尝试找到并执行已经提交的任务,或者是被其他活动任务创建的子任务(如果不存在就阻塞等待)。
这种特性使得 ForkJoinPool 在运行多个可以产生子任务的任务,或者是提交的许多小任务时效率更高。尤其是构建异步模型的 ForkJoinPool 时,对不需要合并(join)的事件类型任务也非常适用。
在 ForkJoinPool 中,线程池中每个工作线程(ForkJoinWorkerThread)都对应一个任务队列(WorkQueue),工作线程优先处理来自自身队列的任务(LIFO或FIFO顺序,参数 mode 决定),然后以FIFO的顺序随机窃取其他队列中的任务。
具体思路如下:
- 每个线程都有自己的一个WorkQueue,该工作队列是一个双端队列。
- 队列支持三个功能push、pop、poll
- push/pop只能被队列的所有者线程调用,而poll可以被其他线程调用。
- 划分的子任务调用fork时,都会被push到自己的队列中。
- 默认情况下,工作线程从自己的双端队列获取任务并执行。
- 当自己的队列为空时,线程随机从另一个线程的队列末尾调用poll方法窃取任务
